
こんにちは、マナです。
今回は、生成AIの仕組みを正しく理解するために大切な「確率モデル」と「ハルシネーション」について解説します。
自然な文章を書いたり、画像や音声を作ったりできる生成AI。でもその裏側では、「もっともらしい言葉の並びを予測する」だけのシンプルな仕組みで動いているんです。
JDLA Generative AI Testでもよく問われるポイントなので、しっかり押さえておきましょう!
🎲 生成AIは“確率モデル”でできている
生成AI、特に大規模言語モデル(LLM)は、確率的な予測を繰り返すことで文章を生成しています。
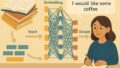
たとえば、次のような文があるとします:
「私は今日、カフェでコーヒーを__。」
この「__」に続く言葉をAIは以下のように予測します:
- 「飲んだ」:70%
- 「買った」:20%
- 「注文した」:10%
この中から確率に応じて1つを選び、次の単語へ…という流れで文章を組み立てていくのが、確率モデルの基本です。
つまり、AIは「理解している」わけではなく、「統計的にそれっぽい言葉」を並べているだけなんです。
🤔 なぜ“嘘”をつく?それが「ハルシネーション」
生成AIは、情報を記憶しているわけではなく、ありそうな文章を生成するため、事実ではない情報を出力してしまうことがあります。
この現象を「ハルシネーション(hallucination)」と呼びます。
ハルシネーションの例:
- 実在しない本や論文を紹介する
- 架空の統計データや法律を提示する
- 存在しない企業名や地名を作り出す
しかも、そういった出力が一見すると正しく見えるのが厄介なポイントです。
📌 なぜハルシネーションが起きるのか?
主な原因は以下のとおりです:
- 確率的予測である
→ AIは「もっともらしい言葉」を並べることが目的で、真偽の判断はしていません。 - 学習データに誤情報が含まれている
→ インターネット上には正確な情報だけでなく、誤った情報も多く存在します。 - 質問が曖昧で明確な答えがない
→ 答えに迷うような質問には、AIが“補って”答えてしまうことがあります。
🛡️ ハルシネーションを防ぐには?
生成AIは便利なツールですが、出力内容を盲目的に信じてはいけません。
以下のような対策が有効です:
- ✅ 人間によるファクトチェック
→ 特にビジネス、教育、医療の分野では必須です。 - ✅ 出典を求めるプロンプトを活用
→ 例:「その情報の出典を教えてください」「根拠を示してください」など。 - ✅ 外部情報との連携(検索型AI)
→ Retrieval-Augmented Generation(RAG)などの手法で、リアルタイム情報を活用。
✅ 試験対策まとめ
Q:確率モデルとは何か?生成AIにおける役割を説明せよ。
→ 確率モデルとは、次に来る単語や内容を統計的に予測するモデル。
生成AIでは、過去のデータから「もっともありそうな出力」を作るために使われている。
Q:ハルシネーションとは何か?その対策を2つ挙げよ。
→ ハルシネーションとは、AIが事実でない情報をもっともらしく生成してしまう現象。
対策としては、①人間による確認、②プロンプトで根拠を要求するなどがある。
📘 ポイント
- 生成AIは「理解」しているのではなく、「確率で予測している」だけ
- ハルシネーションは避けられない現象であることを前提に使う
- 正しい使い方には、AIの仕組みへの理解が欠かせない
このテーマは、仕組みの理解とリスク管理の両方をバランスよく問われる重要なポイントです。
JDLA Generative AI Testでは、「AIをどう使うべきか?」という視点も重視されるので、
ぜひこの内容をしっかり押さえておきましょう!

Comment