こんにちは、マナです。
今回は、生成AIを支える「学習の仕組み」について、4つの重要なキーワードを軸にわかりやすく解説します。
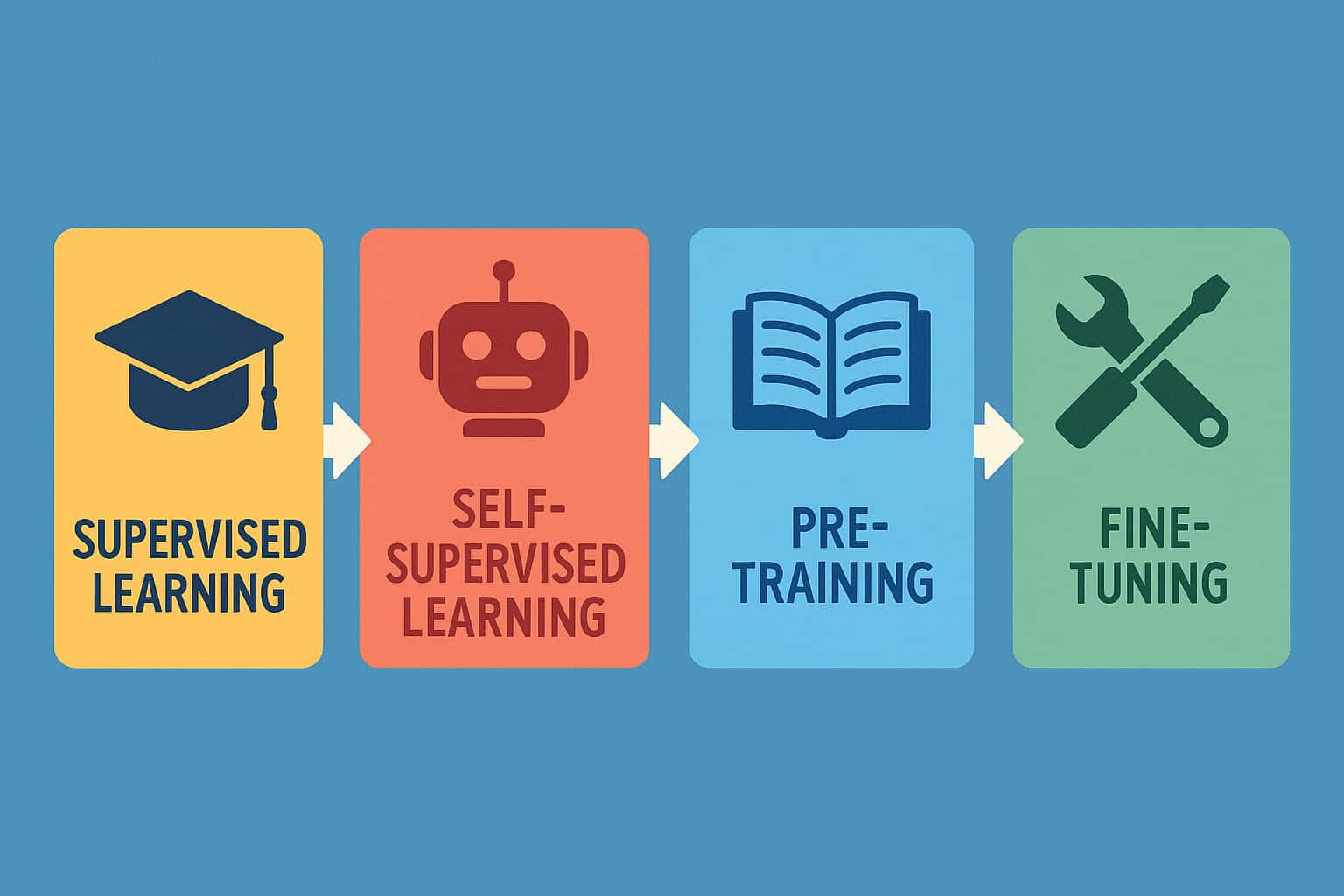
教師あり学習・自己教師あり学習・事前学習・ファインチューニングは、JDLA Generative AI Testでもよく問われるポイントです。
一つひとつの違いや関係性をしっかり押さえておきましょう!
🎓 教師あり学習(Supervised Learning)とは?
教師あり学習は、「正解付きのデータ」を使ってAIに学習させる方法です。
例:
入力:「このメールは迷惑メールですか?」
正解:「はい(スパム)」 or 「いいえ(通常)」
このように、入力と正解(ラベル)のセットを大量に与えることで、AIが判断ルールを学んでいきます。
🔑 特徴:
- 正解が明確なタスク(分類・予測)に適している
- 高精度なモデルを作れるが、大量のラベル付きデータが必要
🤖 自己教師あり学習(Self-Supervised Learning)とは?
自己教師あり学習は、人間の手でラベルをつける代わりに、データの一部を隠して自動的に学習させる手法です。
例:
「私は今日、カフェで〇〇を飲んだ。」
→「〇〇」=「コーヒー」と予測させる
このようなタスクを大量に繰り返すことで、AIは文脈や言葉の意味を学んでいきます。
🔑 特徴:
- ラベルなしのデータで学習可能
- 大規模データに対応しやすく、LLM(大規模言語モデル)でよく使われる
- 事前学習のステップで活用されることが多い
🧠 事前学習(Pre-training)とは?
事前学習は、AIに一般的な知識や言語パターンを学ばせる、最初の土台づくりのフェーズです。
イメージとしては、「百科事典を読んで、世の中のことをざっくり理解する」ような段階です。
🔑 目的:
- 文法・構文などの基礎力を身につける
- 特定のタスクにはまだ対応していない
- 自己教師あり学習がよく使われる
🔧 ファインチューニング(Fine-tuning)とは?
ファインチューニングは、事前学習したモデルに対して、特定のタスクに最適化する調整学習です。
例:
✅ チャット応答に特化
✅ 医療や法律など専門分野に特化
✅ 要約・翻訳・質問応答に特化
🔑 方法と特徴:
- 通常は教師あり学習で行われる
- 小規模なデータでも精度向上が可能
- より実用的なモデルに仕上げるためのステップ
🔄 関係性まとめ:全体の流れを理解しよう
まず、自己教師あり学習という手法を使って、事前学習が行われる。
事前学習で、AIは言葉や知識の基礎モデルを作る。
そのあと、ファインチューニングによって、特定のタスクに合わせたモデルへと仕上げる。
最終的に、実用的なモデルとして社会で活用される。
| 学習手法 | 正解ラベル | 主な用途 | 学習フェーズ |
|---|---|---|---|
| 教師あり学習 | あり | ファインチューニング | 最終段階 |
| 自己教師あり学習 | なし(擬似的) | 事前学習 | 初期段階 |
| 事前学習 | 広く一般的 | 基礎モデル構築 | 学習の出発点 |
| ファインチューニング | あり | 特化応用 | 仕上げ |
✅ 試験対策まとめ
Q:教師あり学習と自己教師あり学習の違いを説明せよ。
→ 教師あり学習は人間が正解ラベルをつけるが、自己教師あり学習はデータの一部を隠して、AIが自動的に正解を予測して学習する。
Q:事前学習とファインチューニングの関係を説明せよ。
→ 事前学習で一般知識を身につけたあと、ファインチューニングで特定のタスクに応じた能力を身につける。基礎→応用の流れ。
📘 おわりに
生成AIの「頭の良さ」は、一度に学んでいるわけではなく、段階的な学習によって作られています。
JDLA Generative AI Testでは、これらの学習手法を正確に区別して理解できるかが問われることも多いです。
ぜひ今回の内容を復習しながら、AIがどうやって“賢く”なっていくのかを、イメージできるようにしておきましょう😊


Comment