你好,我是Mana。
今天我们来一起了解一下生成式AI的核心技术——大型语言模型(LLM: Large Language Model)。
像 ChatGPT、Claude、Gemini 等许多生成式AI,都是以这种LLM为基础运行的。
🔠 什么是“语言模型”?
语言模型是一种可以预测句子中“下一个词(单词或字符)”的模型。
例子:“今天我在咖啡店喝了( )”
→ AI 会预测像“咖啡”或“拿铁”等最合理的词。
为了进行这种预测,LLM 是通过学习大量的文本数据构建出来的。
🧠 LLM 的基本结构
大多数LLM基于一种称为Transformer的架构。
核心结构包括:
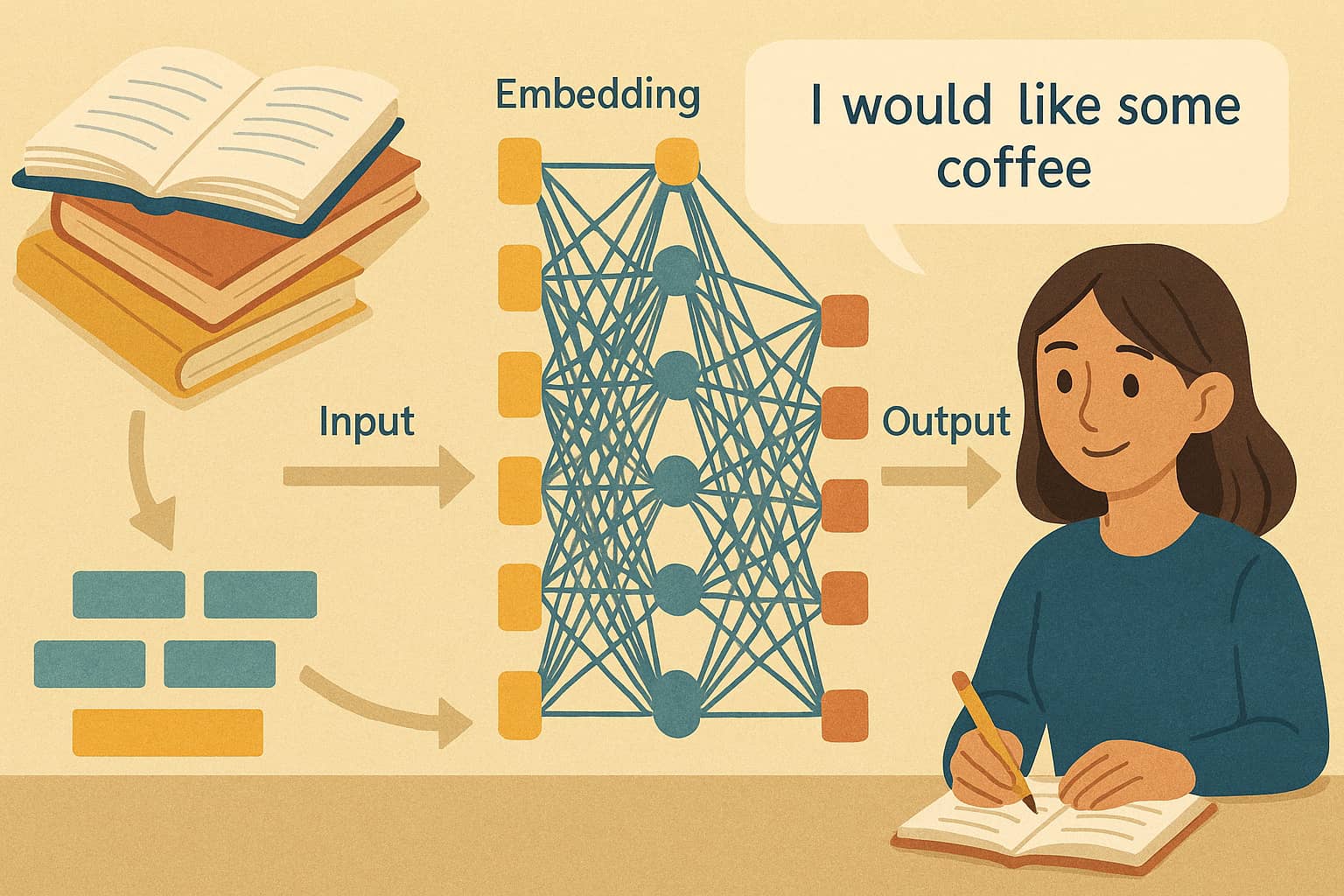
- 分词(Tokenization): 将句子分割为词片段。例如“我使用ChatGPT”会变成[“我”, “使用”, “Chat”, “G”, “PT”]。
- 嵌入(Embedding): 将分词转换为数值向量。例如“咖啡”和“红茶”会在向量空间中靠得很近,表示语义相近。
- 自注意力机制(Self-Attention): 分析句子中词与词的关系。例如在“太郎给花子礼物,她很开心”中,“她”与“花子”的关联会被正确理解。
- 多层结构: LLM 通过数十至数百层网络处理不同层次的信息,从词义到语境理解逐步抽象。
正是这些结构,使得 LLM 能够生成理解上下文的自然语言回应。
📚 LLM 的训练步骤
① 预训练(Pre-training)
- 通过互联网的大量文本数据学习语言模式
- 获得广泛领域的通用知识
- 类似“填空游戏”的方式学习预测词语
② 微调(Fine-tuning)
- 针对特定任务进一步训练模型
- 提高对话、翻译、摘要等方面的性能
③ RLHF(通过人类反馈的强化学习)
- 通过人类评分优化回答质量
- 提升输出的礼貌性、安全性与共情能力
📘 总结
大型语言模型(LLM)是生成式AI的核心技术。理解其结构与训练流程,有助于我们更好地判断AI的输出,并更负责任地使用它们。
今后也让我们一起继续深入学习吧!📘


Comment