你好,我是Mana。
这次我们一起来学习支撑生成式AI的“学习机制”。我会围绕四个关键术语来进行简单易懂的解说。
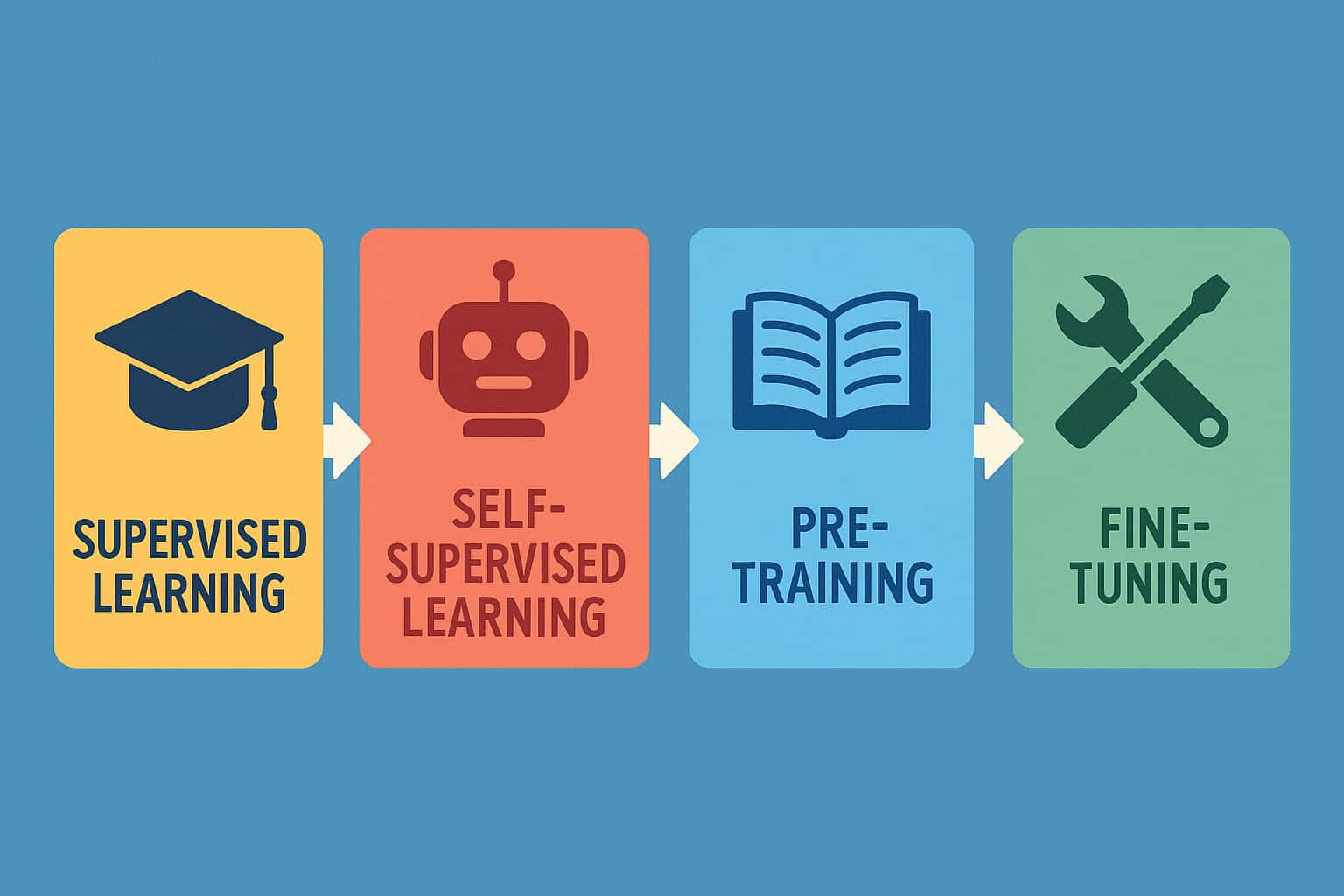
监督学习、自监督学习、预训练、微调是生成式AI发展过程中非常核心的概念。了解它们的区别和联系,有助于我们更好地理解AI是如何“变聪明”的!
🎓 什么是监督学习(Supervised Learning)?
监督学习是一种使用“带有正确答案的数据”来训练AI的方式。
例子:
输入:这封邮件是垃圾邮件吗?
标签:是(垃圾邮件) / 否(正常)
通过大量输入与正确答案(标签)组成的对,AI可以学会判断的规则。
🔑 特点:
- 适合“答案明确”的任务,如分类和预测
- 可训练出高精度模型,但需要大量标注数据
🤖 什么是自监督学习(Self-Supervised Learning)?
自监督学习是一种不依赖人工标签的学习方式,通过“隐藏部分数据”,让AI自己去预测缺失部分来进行训练。
例子:
“我今天在咖啡馆喝了〇〇。”
→ 让AI预测“〇〇”是“咖啡”
通过不断进行这类填空练习,AI逐步掌握语言结构与词义。
🔑 特点:
- 无需人工标注即可训练
- 非常适合大规模数据,常用于大型语言模型(LLM)
- 常作为预训练阶段的方法
🧠 什么是预训练(Pre-training)?
预训练是AI首先进行的训练阶段,目标是让模型掌握通用知识和语言结构,相当于“打基础”。
可以理解为:AI在阅读百科全书,对世界有一个大致的理解。
🔑 目的:
- 建立语言的基础能力(语法、句法)
- 尚未针对具体任务
- 常结合自监督学习进行
🔧 什么是微调(Fine-tuning)?
微调是对经过预训练的模型,进行针对性任务的优化阶段。
例子:
✅ 专门用于聊天对话
✅ 适用于医疗或法律领域
✅ 针对摘要、翻译、问答优化
🔑 方法与特点:
- 通常采用监督学习方式
- 即使使用较少的数据也能提高效果
- 是将模型变得实用的关键步骤
🔄 整体关系图:一图看懂学习流程
首先,使用自监督学习的方法来进行预训练。
在预训练阶段,AI通过学习语言和一般知识,建立基础模型。
然后,通过微调,将模型进一步优化,使其专门适应特定任务。
最后,模型成为一个实用模型,在社会中得到应用。
| 学习方法 | 是否有标签 | 主要用途 | 学习阶段 |
|---|---|---|---|
| 监督学习 | 有 | 微调 | 最后阶段 |
| 自监督学习 | 无(伪标签) | 预训练 | 初期阶段 |
| 预训练 | 通用语言知识 | 建立基础模型 | 学习起点 |
| 微调 | 有 | 任务专用 | 实用阶段 |
📘 总结
生成式AI的“聪明”,并非一蹴而就,而是通过多个阶段的学习逐步获得的。
了解监督学习、自监督学习、预训练和微调的区别,有助于我们更深入理解AI的运作机制。
希望本文能帮助你提升AI素养,一起迈向更智慧的未来!😊


Comment